11 minutes
Sound as an Attack Vector: Introducing phonemenal
![]()
phonemenal is a phonetic similarity and homophone detection library for Python. It is designed for identifying sound-alike collisions across namespaces - package registries, domains, social handles, and anywhere else that a name spoken aloud could be confused for another. The docs can be found at br0k3nlab.com/phonemenal and the source at GitHub .
Some background
This project has roots going back to 2016. During a local SOC training exercise, a parody domain was registered - a catch-all email address was set up to forward to a personal inbox. Almost immediately, sensitive information started flowing in. Real credentials. Real documents. People were typing what they heard or remembered, and the spelling didn’t match up.
That accidental discovery became a mutual research interest between myself and Reagan Short . We spent time digging into the problem space, exploring linguistic patterns, and ultimately presented our findings at TROOPERS 2023 under the title Homophonic Collisions: Hold me Closer Tony Danza. You can watch the full talk here or grab the slides .
The core of the research was this: existing defenses focus on what words look like (typosquatting, homoglyphs), but largely ignore what words sound like. Tools like DNSTwist are great for visual permutations, but they don’t account for the fact that “phlask” and “flask” are pronounced identically, or that someone dictating “numpy” over the phone could easily end up with “numpie” on the other end.
phonemenal is the tooling that grew out of that research.
The problem: homophonic collisions
A homophonic collision occurs when two distinct strings share the same (or nearly the same) pronunciation. There are a few levels to this:
- Exact homophones - words that are phonetically identical: blue / blew, right / write, new / knew
- Near-homophones - words that are phonetically very close: crowd / crown, page / rage, elastic / fantastic
- Soundsquatting - the weaponized exploitation of homophonic collisions for malicious purposes
The diagram below illustrates just how many points of failure exist in the communication chain - from the speaker’s intended message to the listener’s interpretation. Every one of these is a potential collision point.
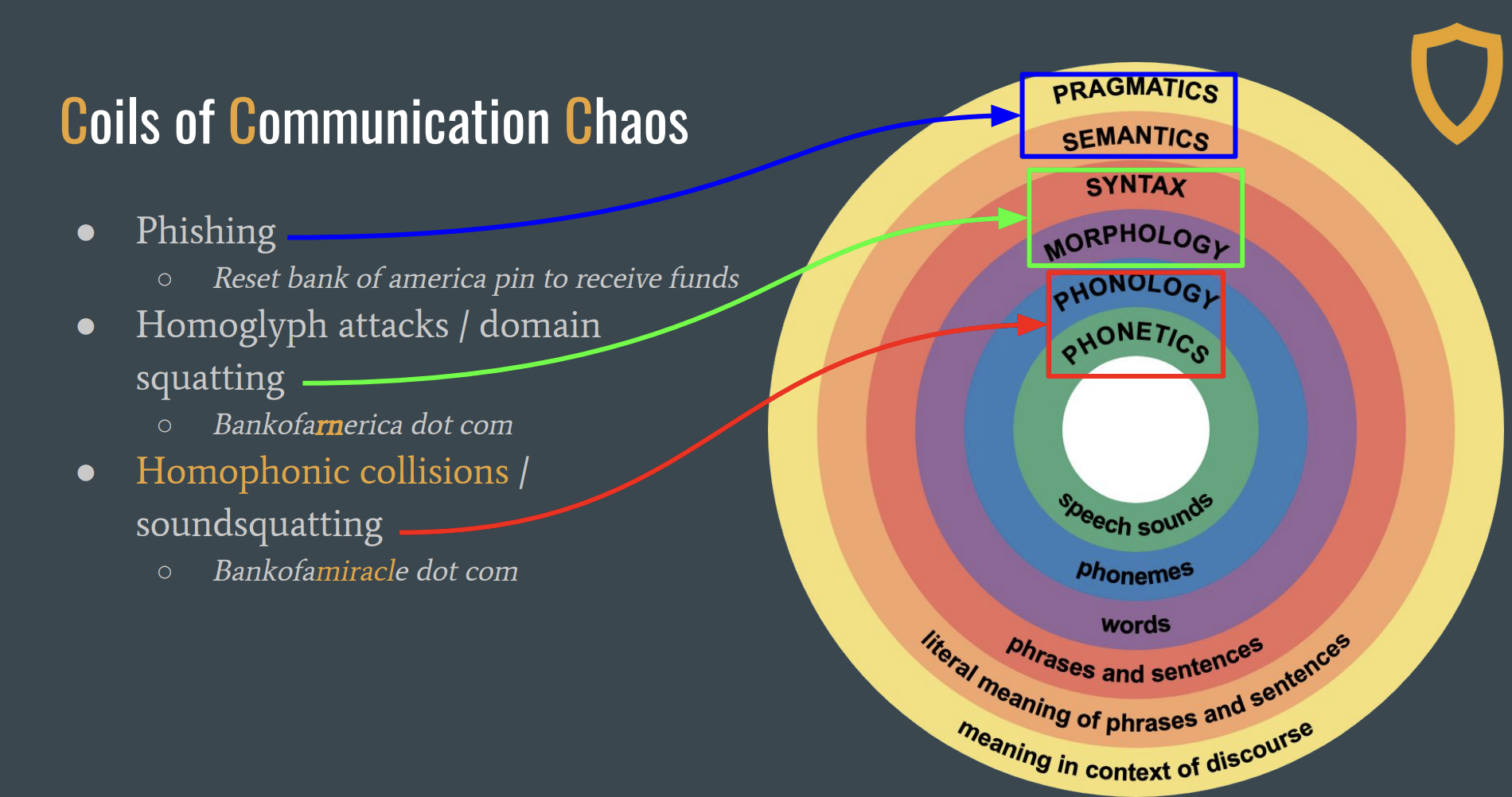
Coils of Communication Chaos - adapted from the UW Linguistics Research Guide
That last one is where it gets interesting from a security perspective. If an attacker registers numpie on PyPI,
or walmaret.com as a domain, or phlask as a package name - these are not typos. They are phonetically equivalent
names designed to exploit the gap between what we hear and what we type.
During our research, we found real-world examples across multiple namespaces:
- Domains (from the Alexa top 1000):
walmaret.com,yootube.com,webbex.com,wellesfarago.com - PyPI packages: soundsquat variants of popular packages, some validated as malicious
- Voice assistants and LLMs: speech-to-text and text-to-speech wrappers that silently introduce collision errors
The attack surface grows every time a human speaks a name and someone else types it. And with voice assistants and LLM integrations becoming increasingly prevalent, the risk surface is expanding.
See it in action
The explorer below shows pre-computed phonetic breakdowns for real examples across different categories. Click any pair to expand the phoneme details. Pay attention to the Package Squats and Domain Squats tabs - these are the kinds of collisions phonemenal is built to detect.
How phonemenal works
The library provides three complementary scoring algorithms, all normalized to a 0.0–1.0 range:
PPC-A (Positional Phoneme Correlation - Absolute) builds positional phoneme combinations by traversing forward and reverse directions with padding, then measures set intersection. It captures how much of the positional phoneme structure two words share.
PLD (Phoneme Levenshtein Distance) operates at the syllable level, using CMU dict stress markers to split phonemes into syllable groups. Each syllable is an atomic unit, so the distance reflects how many whole syllables differ - this is closer to how we actually perceive speech.
LCS (Longest Common Subsequence) computes the ratio of the longest common subsequence to the total sequence length. Simple, effective, and robust to insertions.
A composite score combines all three with configurable weights.
For words not in the CMU Pronouncing Dictionary (think: brand names, neologisms, package names like numpy or
pytorch), phonemenal uses a fallback encoder - a simplified Metaphone-inspired encoding that applies digraph
replacement, vowel normalization, and character collapsing to produce phonetic keys. Sound-alike names produce the same
or similar keys.
from phonemenal import fallback
fallback.phonetic_key("numpy") # → "nAmpY"
fallback.phonetic_key("numpie") # → "nAmpY" - exact match
fallback.phonetic_key("flask") # → "flAsk"
fallback.phonetic_key("phlask") # → "flAsk" - exact match
fallback.phonetic_key("phone") # → "fAn"
fallback.phonetic_key("fone") # → "fAn" - exact match
Getting started
pip install phonemenal
# With LLM support for deep analysis
pip install phonemenal[llm]
The API is intentionally straightforward. Here are the core operations:
from phonemenal import similarity, homophones, variants, splitting, scanning
# -- Similarity scoring (all 0.0–1.0) --
similarity.ppc("crowd", "crown") # PPC-A score
similarity.pld("elastic", "fantastic") # syllable-level edit distance
similarity.lcs("packaging", "packages") # longest common subsequence
similarity.composite("crowd", "crown") # weighted average of all three
# -- Exact homophones --
homophones.find("blue") # → ["blew"]
homophones.find("right") # → ["rite", "wright", "write"]
# -- Near-homophones --
homophones.find_similar(
"crowd",
candidates=["crown", "crowed", "crude"],
min_score=0.7
)
# -- Variant generation --
variants.generate("flask") # → {"phlask", "flazk", ...}
variants.generate_morphological("click") # → {"clicked", "clicker", "clicks", ...}
# -- Compound word splitting --
splitting.split("bluevoyage") # → ["blue", "voyage"]
splitting.homophone_permutations("bluevoyage") # → ["bluevoyage", "blewvoyage", ...]
The CLI
phonemenal ships with a CLI that uses Rich for formatted output:
# Compare two words across all algorithms
phonemenal similarity crowd crown
# Specific algorithm
phonemenal similarity crowd crown -a ppc
# Find exact homophones
phonemenal homophones blue
# Generate sound-alike variants
phonemenal variants flask -m # include morphological variants
# Split compound words and show permutations
phonemenal split bluevoyage -p
# Full comparison report
phonemenal compare crowd crown
# JSON output for scripting
phonemenal compare crowd crown -j
Scanning at scale
The real power shows up when you need to check names against a known set. The scanning pipeline combines forward matching, variant generation, and optional reverse verification:
from phonemenal.scanning import scan, scan_with_reverse, format_matches
# Forward scan: check candidates against known names
matches = scan(
candidates=["numpie", "phlask", "klik"],
known_names=["numpy", "flask", "click"],
threshold=0.75
)
print(format_matches(matches))
# [!!!] 'numpie' ~ 'numpy' (score: 1.00, type: exact_phonetic, keys: nAmpY / nAmpY)
# [!!!] 'phlask' ~ 'flask' (score: 1.00, type: exact_phonetic, keys: flAsk / flAsk)
# [!!!] 'klik' ~ 'click' (score: 1.00, type: exact_phonetic, keys: klAk / klAk)
For reverse scanning, you can provide a lookup function to check if generated variants actually exist in the wild:
import httpx
def check_pypi(name: str) -> bool:
"""Check if a package exists on PyPI."""
resp = httpx.head(f"https://pypi.org/project/{name}/", follow_redirects=True)
return resp.status_code == 200
matches = scan_with_reverse(
candidates=["numpy"],
known_names=["numpy"],
exists_fn=check_pypi,
threshold=0.75,
include_morphological=True
)
This is where it starts to get practical for real defensive operations - monitoring package registries, domain registrations, or any namespace where soundsquatting could be a vector.
LLM-powered deep analysis
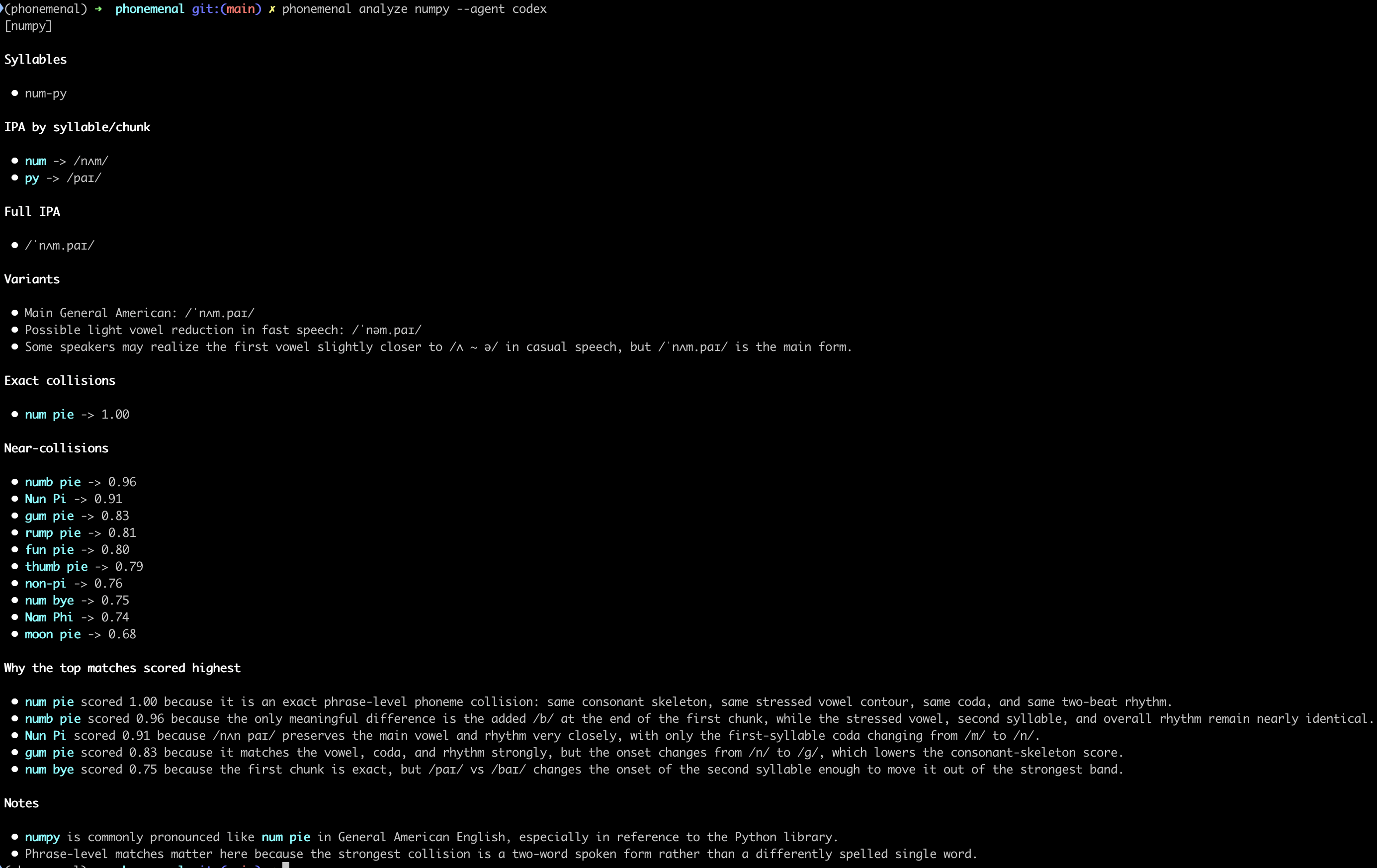
For cases where algorithmic scoring is ambiguous, phonemenal supports optional LLM-powered analysis. It can break down syllables, generate IPA transcriptions, and score using a weighted phonetic model:
# Anthropic API
phonemenal analyze numpy --provider anthropic
# OpenAI API
phonemenal analyze numpy --provider openai
The LLM integration over API / remote models is entirely optional - the core library has zero external API dependencies. Instead, you can pass the analysis off to a local agent from within phonemenal, or just handoff the prompt. The benefit of this approach is it is built into the core library, with no extras or auth requirements.
# Pipe to a local agent
phonemenal analyze numpy --agent claude
# Just get the prompt (for piping to your own workflow)
phonemenal prompt numpy | pbcopy
Real-world validation: scanning known malicious packages
While building out a supply chain monitoring and analysis framework, I integrated homophonic collision detection into the process. It was then that I decided to dust off the POCs from our research and release the phonemenal library.
To further put this to the test, I ran phonemenal against the DataDog Malicious Software Packages Dataset - a curated collection of known malicious packages from PyPI and npm (credit to DataDog for maintaining this dataset). The goal was simple: scan the names of known malicious packages against popular legitimate packages to see how many are phonetically similar - potential soundsquats hiding in plain sight.
NOTE: only the package names from the manifest were used in this analysis. The actual malicious samples were not downloaded or executed.
PyPI results
1,786 known malicious package names scanned against the top ~125 most popular PyPI packages:
| Threshold | Matches | Unique Candidates |
|---|---|---|
| >= 1.00 (exact) | 11 | 11 |
| >= 0.90 | 43 | 42 |
| >= 0.80 | 125 | 118 |
| >= 0.70 | 381 | 300 |
56.9% of the malicious packages had at least one phonetic match (>= 0.60) against a popular package. At the strictest threshold (exact phonetic key match), 11 packages were dead ringers:
| Malicious | Target | Score | Keys |
|---|---|---|---|
| aiiohttp | aiohttp | 1.00 | Ahtp / Ahtp |
| aiohtttp | aiohttp | 1.00 | Ahtp / Ahtp |
| beautifulsup4 | beautifulsoup4 | 1.00 | bAtAfAlsAp4 / bAtAfAlsAp4 |
| botoceor | botocore | 1.00 | bAtAcAr / bAtAcAr |
| coloroma | colorama | 1.00 | cAlArAmA / cAlArAmA |
| colurama | colorama | 1.00 | cAlArAmA / cAlArAmA |
| djangoo | django | 1.00 | djAngA / djAngA |
| flaask | flask | 1.00 | flAsk / flAsk |
| reuquests | requests | 1.00 | rAkwAsts / rAkwAsts |
| ritch | rich | 1.00 | rAc / rAc |
| selenim | selenium | 1.00 | sAlAnAm / sAlAnAm |
Near matches (score 0.87 – 0.97) (expand for details)
| Malicious | Target | Score | Keys |
|---|---|---|---|
| importlib-metadate | importlib-metadata | 0.97 | AmpArtlAbmAtAdAt / AmpArtlAbmAtAdAtA |
| typing-extension | typing-extensions | 0.96 | tYpAngAxtAnsn / tYpAngAxtAnsns |
| python-dateuti | python-dateutil | 0.96 | pYtAndAtAtA / pYtAndAtAtAl |
| matplotlibp | matplotlib | 0.95 | mAtplAtlAbp / mAtplAtlAb |
| setuptolos | setuptools | 0.95 | sAtAptAlAs / sAtAptAls |
| tensrflow | tensorflow | 0.95 | tAnsrflAw / tAnsArflAw |
| aiopbotocore | aiobotocore | 0.94 | ApbAtAcAr / AbAtAcAr |
| colouramas | colorama | 0.94 | cAlArAmAs / cAlArAmA |
| pydantics | pydantic | 0.94 | pYdAntAcs / pYdAntAc |
| requesrts | requests | 0.94 | rAkwAsrts / rAkwAsts |
| requestsx | requests | 0.94 | rAkwAstsx / rAkwAsts |
| requesuts | requests | 0.94 | rAkwAsAts / rAkwAsts |
| requesxts | requests | 0.94 | rAkwAsxts / rAkwAsts |
| pckaging | packaging | 0.93 | pkAgAng / pAkAgAng |
| requeste | requests | 0.93 | rAkwAst / rAkwAsts |
| typing-extnesions | typing-extensions | 0.93 | tYpAngAxtnAsns / tYpAngAxtAnsns |
| btoocore | botocore | 0.92 | btAcAr / bAtAcAr |
| ulrlib3 | urllib3 | 0.92 | AlrlAb3 / ArlAb3 |
| cryptograohy | cryptography | 0.91 | crYptAgrAhY / crYptAgrAfY |
| cryptographz | cryptography | 0.91 | crYptAgrAfz / crYptAgrAfY |
| pandaai | pandas | 0.91 | pAndA / pAndAs |
| s4transfer | s3transfer | 0.90 | s4trAnsfAr / s3trAnsfAr |
| aiohtttps | aiohttp | 0.89 | Ahtps / Ahtp |
| pyyal | pyyaml | 0.89 | pYAl / pYAml |
| colorara | colorama | 0.88 | cAlArArA / cAlArAmA |
| colormore | colorama | 0.88 | cAlArmAr / cAlArAmA |
| colotama | colorama | 0.88 | cAlAtAmA / cAlArAmA |
| dequests | requests | 0.88 | dAkwAsts / rAkwAsts |
| fequests | requests | 0.88 | fAkwAsts / rAkwAsts |
| gequests | requests | 0.88 | gAkwAsts / rAkwAsts |
| r3quests | requests | 0.88 | r3kwAsts / rAkwAsts |
| r4quests | requests | 0.88 | r4kwAsts / rAkwAsts |
| requesfs | requests | 0.88 | rAkwAsfs / rAkwAsts |
| requesks | requests | 0.88 | rAkwAsks / rAkwAsts |
| requestn | requests | 0.88 | rAkwAstn / rAkwAsts |
| requestr | requests | 0.88 | rAkwAstr / rAkwAsts |
| tequests | requests | 0.88 | tAkwAsts / rAkwAsts |
| matplotlib-req | matplotlib | 0.87 | mAtplAtlAbrAq / mAtplAtlAb |
The requests library alone had 20+ phonetically similar malicious variants in the dataset - everything from
simple transpositions (reuquests, requesrts) to onset substitutions (fequests, dequests, tequests).
npm results
9,505 known malicious package names scanned against ~120 popular npm packages:
| Threshold | Matches | Unique Candidates |
|---|---|---|
| >= 1.00 (exact) | 3 | 3 |
| >= 0.90 | 31 | 31 |
| >= 0.80 | 236 | 223 |
| >= 0.70 | 1,207 | 967 |
38.4% of the malicious set had phonetic matches. The 3 exact hits:
| Malicious | Target | Score | Keys |
|---|---|---|---|
| naniod | nanoid | 1.00 | nAnAd / nAnAd |
| pupeter | puppeteer | 1.00 | pApAtAr / pApAtAr |
| pupetier | puppeteer | 1.00 | pApAtAr / pApAtAr |
The typescript package was a particularly heavy target with 15+ versioned squats
(typescript-5.5, typescript-5.6, typescript-go, etc.).
Near matches (score 0.82 – 0.96) (expand for details)
| Malicious | Target | Score | Keys |
|---|---|---|---|
| suport-color | supports-color | 0.96 | sApArtcAlAr / sApArtscAlAr |
| typescript-5.5 | typescript | 0.95 | tYpAscrApt5 / tYpAscrApt |
| node-multer | nodemailer | 0.95 | nAdAmAltAr / nAdAmAlAr |
| eslint-8 | eslint | 0.92 | AslAnt8 / AslAnt |
| eslint-9 | eslint | 0.92 | AslAnt9 / AslAnt |
| jsonwebjstoken | jsonwebtoken | 0.92 | jsAnwAbjstAkAn / jsAnwAbtAkAn |
| peritter | prettier | 0.92 | pArAtAr / prAtAr |
| boby_parser | body-parser | 0.90 | bAbYpArsAr / bAdYpArsAr |
| axio.js | axios | 0.89 | AxAjs / AxAs |
| deezcord.js | discord.js | 0.89 | dAzcArdjs / dAscArdjs |
| dezcord.js | discord.js | 0.89 | dAzcArdjs / dAscArdjs |
| dizcordjs | discord.js | 0.89 | dAzcArdjs / dAscArdjs |
| inquirer-js | inquirer | 0.89 | AnkwArArjs / AnkwArAr |
| nodemail-lite | nodemailer | 0.89 | nAdAmAlAt / nAdAmAlAr |
| date-fns.js | date-fns | 0.88 | dAtAfnsjs / dAtAfns |
| mongodb-cd | mongodb | 0.88 | mAngAdbcd / mAngAdb |
| mongodb-ci | mongodb | 0.88 | mAngAdbcA / mAngAdb |
| node-fetch-v3 | node-fetch | 0.88 | nAdAfAcv3 / nAdAfAc |
| nodemonjs | nodemon | 0.88 | nAdAmAnjs / nAdAmAn |
| zustand.js | zustand | 0.88 | zAstAndjs / zAstAnd |
| jsonapptoken | jsonwebtoken | 0.87 | jsAnAptAkAn / jsAnwAbtAkAn |
| cross-session | cross-env | 0.86 | crAsAsn / crAsAnv |
| express-v4 | express | 0.86 | AxprAsv4 / AxprAs |
| js-prettier | prettier | 0.86 | jsprAtAr / prAtAr |
| prettierjs | prettier | 0.86 | prAtArjs / prAtAr |
| socket.io.js | socket.io | 0.86 | sAkAtAjs / sAkAtA |
| webpikes | webpack | 0.86 | wAbpAkAs / wAbpAk |
| playwright-1.45 | playwright | 0.84 | plAYrAgt145 / plAYrAgt |
| playwright-1.46 | playwright | 0.84 | plAYrAgt146 / plAYrAgt |
| playwright-1.47 | playwright | 0.84 | plAYrAgt147 / plAYrAgt |
| dotevn | dotenv | 0.83 | dAtAvn / dAtAnv |
| eth-errors | ethers | 0.83 | AtArArs / AtArs |
| etherdjs | ethers | 0.83 | AtArdjs / AtArs |
| nanoid-js | nanoid | 0.83 | nAnAdjs / nAnAd |
| opresc | express | 0.83 | AprAsc / AxprAs |
| debug-mj | debug | 0.83 | dAbAgmj / dAbAg |
| debugr1 | debug | 0.83 | dAbAgr1 / dAbAg |
| prsima | prisma | 0.82 | prsAmA / prAsmA |
| stgripe | stripe | 0.82 | stgrAp / strAp |
| multerjs | multer | 0.82 | mAltArjs / mAltAr |
| sequelize-v7 | sequelize | 0.82 | sAkwAlAzv7 / sAkwAlAz |
Here is what a real scan against the DataDog dataset looks like in practice:
import json
import httpx
from phonemenal.scanning import scan, format_matches
# Load malicious package names from DataDog manifest (names only!)
resp = httpx.get(
"https://raw.githubusercontent.com/DataDog/"
"malicious-software-packages-dataset/main/samples/pypi/manifest.json"
)
malicious_names = list(resp.json().keys())
# Scan against popular packages
popular = ["requests", "flask", "numpy", "django", "selenium", "colorama",
"beautifulsoup4", "aiohttp", "botocore", "cryptography"]
matches = scan(candidates=malicious_names, known_names=popular, threshold=0.80)
print(format_matches(matches))
These are not hypothetical results. These are real malicious packages, confirmed by DataDog’s GuardDog analysis, that phonemenal correctly flags as phonetically suspicious.
What’s next?
As I mentioned above, I am integrating it into a supply chain monitoring framework at the moment, but there are lots of other use cases for detecting and preventing sound as an attack vector, especially with voice assistants coming back into popularity as part of the genAI craze.
phonemenal is still early and there is more to explore. Acoustic analysis approaches, dialect-aware detection, expanded namespace coverage, and deeper integration with package registry monitoring are all on the horizon.
If this is a problem space that interests you, check out the docs , the repo , or the TROOPERS talk for the full research background. Contributions and ideas are welcome.
phonemenal homophones soundsquatting homophonic collisions supply chain security detection engineering phonetics
2338 Words
2026-04-06 17:00